
I had an issue with a four node DAG where the DR site with two of the DAG members were having replication issues. It was only technically affecting one DAG Member though. The copy queue length was really high and the logs were not committing to the database. A Test-ReplicationHealth cmdlet test told that the copy queue length for the affected database copy was high. No other databases were affected as there were eight databases on this DAG Node. The issue was that the log files were not replicating properly to the one DAG member for that database, causing the log file drives on all the other DAG members to build and become full:
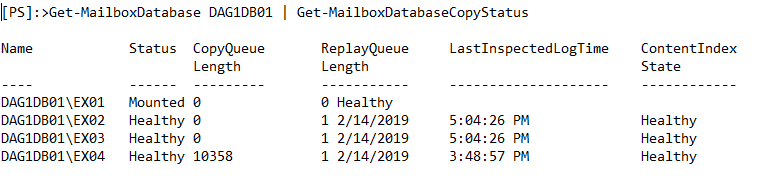
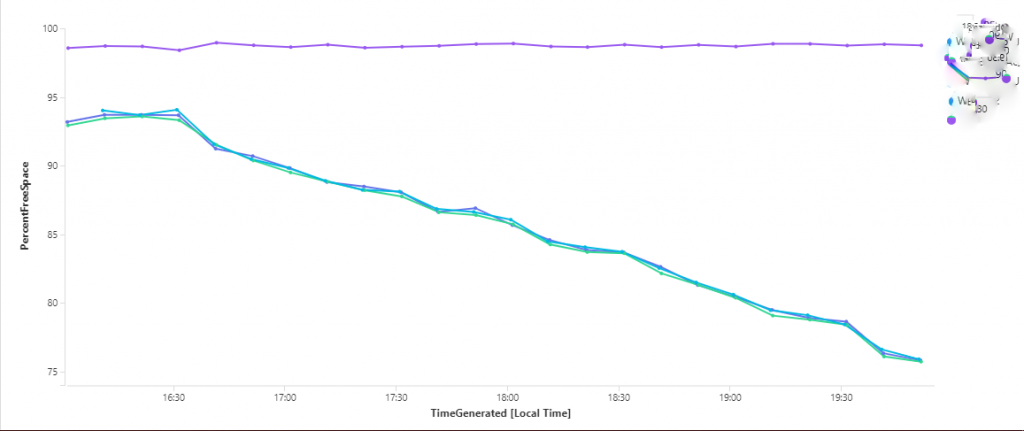
Circular Logging was turned on, but since the db was NOT in sync, the logs could NOT truncate properly which rendered CL useless. What was being done to stave the issue was to suspend the database copy of the affected DAG member (EX04), then resume the copy. The logs would replay and commit to the database copy on the DAG member, but over a short period of time, the same issue would arise again, as shown in this graph:
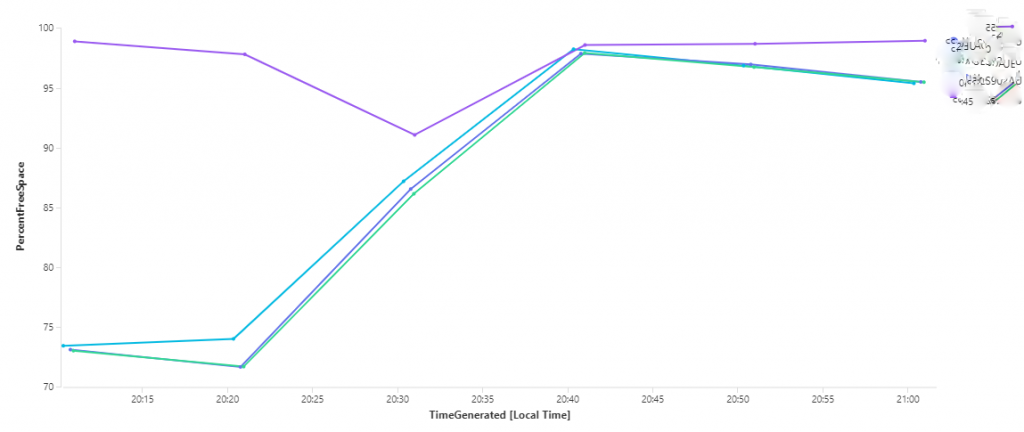
There were absolutely no errors in the Event Viewer showing this replication issue. After some research, I ran the following cmdlet showing a particular output parameter that gave me the actual problem:
Get-MailboxDatabaseCopyStatus DAG1DB01 | ft -a -wr Name, Status, IncomingLogCopyingNetwork

The operative error here was: {An error occurred while communicating with server ‘EX01’. Error: Unable to read data from the transport connection: An established connection was aborted by the software in your host machine.}
Now even though only EX04 was actually having problems with its log replication, both DR members EX03 & EX04 were having the same problem. Again, there were NO events in event viewer showing this issue. I next did some connectivity tests to EX01 from EX04 even though the error said there was an established connection that was broken.
Ping EX01 -f -l 1472
Now the -f states do NOT fragment the packet and send it as a whole to the destination.
The -l states the packet/buffer size you want sent. In this case 1472 bits.
By doing this, you are able to assure that a router or switch is NOT segmenting the packets, packet segmentation of replication logs can cause data corruption and replication issues.
That test passed successfully. I also did a trace route to assure there was no packet loss on the route to the replicating server. That test passed successfully.
I next checked the DAG Network to assure that all networks were working for replication. Now, in this scenario, there was only ONE DAG Network, there was NOT a separate Replication Network. I did not design the DAG and limitations most likely came into play during the design. From my experience, you setup a separate replication network for replication only, but if your network has enough bandwidth, and the design calls for simplification, you can use one DAG network in your design.
Get-DatabaseAvailabilityGroupNetwork | fl
RunspaceId : a1600003-8074-4000-9150-c7800000207f
Name : MapiDagNetwork
Description :
Subnets : {{192.168.1.0/24,Up}, {192.168.2.0/24,Up}}
Interfaces : {{EX01,Up,192.168.1.25}, {EX02,Up,192.168.1.26},{EX03,Up,192.168.2.25}, {EX04,Up,192.168.2.26}}
MapiAccessEnabled : True
ReplicationEnabled : True
IgnoreNetwork : False
Identity : DAG1\MapiDagNetwork
IsValid : True
ObjectState : New
All the DAG Network Members were up and not showing errors. I next did a telnet session to EX01 over the default DAG replication port 64327 to see if there would be any connectivity issues to EX01:
telnet EX01 64327
That test was successful and there were no connectivity issues to EX01 from EX04. Again, there was only ONE database out of eight that was having replication problems. After mulling over the problem, it was decided to restart the MSExchangeRepl service on EX03 AND EX04 since the error was present on both DAG members. We would then, suspend the database copy and resume the database copy on the affected servers.
Run on EX03:
Restart-Service MSExchangeRepl
Suspend-MailboxDatabaseCopy DAG1DB01/EX03 -Confirm:$False
Resume-MailboxDatabaseCopy DAG1DB01/EX03 -Confirm:$False
Run on EX04:
Restart-Service MSExchangeRepl
Suspend-MailboxDatabaseCopy DAG1DB01/EX04 -Confirm:$False
Resume-MailboxDatabaseCopy DAG1DB01/EX04 -Confirm:$False
After monitoring the databases and log drives, the issue was resolved and replication started functioning properly.
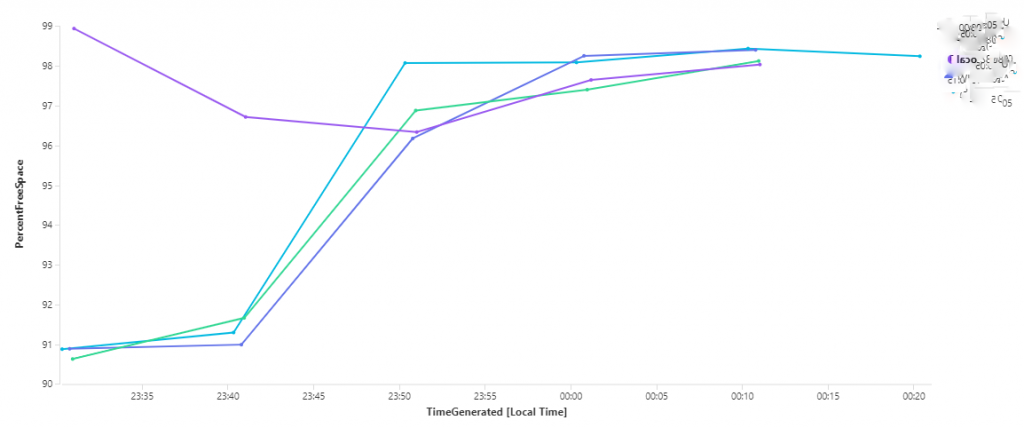
Hi,
I have two distinct DAG networks. one for Replication and another one MAPI. All networks seems to be communicating fine as per the above tests you mentioned. after following the above fix, the issue goes away for some time before it i se it again.